
이번 포스트에서는 TCP/IP 프로토콜의 3계층인 네트워크 계층의 IP 프로토콜을 정리하겠습니다.
IP (인터넷 프로토콜)
인터넷 프로토콜(IP, Internet Protocol)은 목적지까지 데이터를 전달하는 기능을 수행하고 동시에 주소를 관리하는 기능을 수행합니다.
집 주소가 있어야 우편을 보낼 수 있듯이, 네트워크에 접속된 각 컴퓨터에도 고유한 식별 번호가 있어야 정확하게 데이터를 송수신할 수 있습니다. 따라서 인터넷에 연결된 모든 컴퓨터에는 고유 주소가 부여되는데 이것이 IP 주소 입니다.
IP datagram 포맷

IP 데이터는 TCP or UDP로 부터 받은 데이터(payload)에 네트워크 계층에서 필요한 정보들이 header에 덧붙여집니다.
헤더의 정보는 아래와 같습니다.
ver -> IPv4의 주소체계 혹은 IPv6의 주소체계 중에 어떤 버전을 사용하고있는지를 나타냅니다.
head length -> 헤더의 길이(bytes)입니다. 데이터 한 줄이 32bits(4bytes)라고 적혀있으므로 5줄 * 4bytes 총 20bytes가 IP의 기본적인 헤더 길이가 됩니다.
type of service -> IP 데이터의 타입을 표시합니다. 요즘은 거의 사용되지 않습니다. 원래는 인터넷과 TCP/IP 프로토콜이 미국 국방부에서 처음 만들어지고 그에 맞는 필드들이 설계되었는데 그 당시에는 긴급인지 아닌지 등의 정보를 표시하였다고 합니다.
length -> 전체 데이터의 길이를 나타냅니다.
16-bit identifier, flags, fragment offset -> 이 세가지 필드는 단편화(fragmentation)와 재결합(reassembly)을 위해 사용합니다. 정확히 말하면 네트워크를 지나는 데이터들은 때에 따라서 잘게 쪼개졌다가 합쳐질 수 있는데 그 때 잘려진 조각들을 표시하고 합치기 위해 사용합니다.
time to live -> TTL 약자입니다. 데이터가 건너갈 수 있는 남아있는 hop 수를 표시합니다. 라우터를 하나 건너가는 것을 한 hop이라고 합니다. ex) 만약 처음에 200개의 hop을 할당 받은 상태라고 가정하면, 데이터가 라우터를 건너갈때 마다 TTL 필드의 값이 점점 줄어들고 만약 TTL 필드값이 0이 되면 데이터의 수명이 다한 것으로 간주하고 라우터에서 해당 데이터를 제거하고 해당 데이터가 출발한 곳에 어떤 라우터에서 제거되었다고 알려줍니다. TTL은 일반적으로 여유있게 설정합니다.
upper layer -> IP 위에 존재하는 전송(Transport) 계층의 프로토콜을 표시합니다(TCP or UDP). 혹은 ICMP 프로토콜이 될 수도 있습니다.
header checksum -> 받은 데이터에 에러가 있는지 없는지 에러 검출을 하기 위해 사용합니다. TCP의 경우 신뢰성있는 데이터 전송을 위해 한 비트라도 에러가 있으면 재전송합니다. UDP도 checksum 계산을 하지만 오류를 정정해주는 기능은 없습니다. 필드명이 header checksum인 이유는 전송 계층에서 내려온 데이터는 checksum 계산을 하지 않고 header에 대해서만 에러 검출 동작을 하기 때문입니다.
sorurce, dest IP address -> 가장 중요한 부분으로 출발지와 목적지 IP 주소입니다. 32bits인 이유는 IPv4를 사용하기 때문입니다.
options -> 추가적인 정보를 기록합니다. 예를 들면, 특정 라우터를 지나간 timestamp 등이 필요하다면 옵션에 추가하면 됩니다. 하지만, 추가적인 옵션이 없는 경우에는 기본적으로 헤더의 크기는 20bytes 입니다.
data -> 전송 계층에서 내려온 데이터(payload)입니다.
IP 단편화 및 재결합

위의 그림은 1개의 큰 datagram이 3개의 작은 datagram으로 잘개 쪼개지고 합쳐지는 것을 표현한 것입니다.
네트워크 링크에서는 MTU(Maximum Transmission Unit) 사이즈가 있습니다. 즉, 데이터의 최대 크기가 존재하며 MTU 사이즈는 네트워크 링크의 종류에 따라 다릅니다. 예를 들면, Wifi와 Ethernet은 MTU 사이즈가 다르며 Ethernet은 MTU 사이즈가 1500bytes 로 정해져있습니다.
단편화(fragmentation) -> 만약, 큰 MTU 사이즈를 가진 네트워크에서 작은 MTU 사이즈를 가진 네트워크로 데이터를 이동시켜야 한다면 데이터를 잘게 쪼개야 합니다.
재결합(reassembly) -> IP header에는 쪼개진 datagram 조각의 순서를 식별하기위한 필드가 포함되어있습니다. 쪼개진 datagram을 마지막 도착지에서 쪼개진 데이터를 다시 합치는 것을 재결합(reassembly)이라고 합니다.
IPv4 주소체계

IPv4는 32비트(bit)로 구성되어있으며 한 칸당 10진수 8bit의 IP 주소로 구성되어 있습니다.
e.g) 223. 92. 0. 1
이 IP 주소는 호스트 or 라우터의 네트워크 인터페이스마다 하나씩 존재합니다. 하지만, 라우터 혹은 호스트의 대부분은 두 개 이상의 네트워크 인터페이스가 존재하므로 IP 주소도 여러개 존재할 수 있습니다.
서브넷(subnets)
32비트의 IP 주소는 크게 두 부분으로 나뉩니다.
1. 서브넷(subnet)을 나타내는 부분 - 상위 bits
2. 네트워크 안에서의 호스트(host)를 나타내는 부분 - 하위 bits
여기서 서브넷(subnet)이란 IP 주소에서 동일한 장치의 인터페이스를 말하고 하나의 서브넷 안에서는 라우터 없이 연결되어있으므로 동일한 LAN(이더넷 or Wifi) 안에 존재해서 상호간에 물리적으로 연결되어 있습니다. 그러므로 중계 라우터 없이도 서로 물리적으로 도달하는 것이 가능합니다. 그리고 호스트(host)는 특정 서브넷 안에서의 구체적인 호스트의 번호를 나타냅니다.
서브넷 마스크(subnet mask) -> 상위 몇 비트(bit)까지 서브넷을 사용할 것인가를 나타내며 슬래시(/)로 나타냅니다.
ex)223.1.3.0/24 라는 서브넷 마스크가 의미하는 것은 상위 24비트(3칸)까지 서브넷으로 사용하겠다는 것을 의미합니다. 또한 여기서 223.1.3.0과 같이 마지막 8비트가 0인데 이것은 0번 호스트를 나타내는 것이 아니라 네트워크(서브넷) 자체의 주소를 의미하는 것입니다.
CIDR(Classless Inter-Domain Routing) -> IETF에서 1993년부터 도입한 표준 IP 주소 할당 방식으로 8, 16, 24 비트로 나누는 것이 아니라 23비트 15비트 등으로 서브넷을 구분합니다. CIDR은 고갈되는 IP 주소를 기존의 클래스 기반 IP 주소 할당 방식보다 더 효율적으로 사용할 수 있는 장점이 있습니다. CIDR 도입 이후 이전의 클래스 기반 방식은 사용하지 않기 때문에 클래스 없는 도메인 간 라우팅 기법이라고도 불립니다.
또한, 255.255.255.255는 서브넷에 속해있는 모든 호스트에게 보낼 수 있는 브로드캐스트(Broadcast) 주소를 의미합니다.
호스트가 IP 주소를 할당받는 방법 두 가지
1. 관리자가 수동으로 시스템 파일에 저장하는 방법(고정 IP 주소)
2. DHCP(Dynamic Host Configuration Protocol)를 통해 동적으로 IP 주소를 할당받는 방법입니다.(유동 IP 주소)
ex) 예를 들면, 어떤 사람이 카페에 가면 특정 서브넷에 접속하고 그 사람은 IP 주소가 필요하므로 카페에서 동적으로 IP 주소를 할당받고 나가면 IP 주소를 반납합니다.
DHCP(Dynamic Host Configuration Protocol)
DHCP(Dynamic Host Configuration Protocol)는 클라이언트에게 동적으로 IP 주소를 할당하는 방법을 제공하는 프로토콜입니다.
DHCP의 특징
- 사용중인 주소의 대여기간 갱신(연장) 가능
- 주소의 재사용 가능
- 네트워크에 접속하고자 하는 이동 사용자 지원
DHCP의 동작 과정
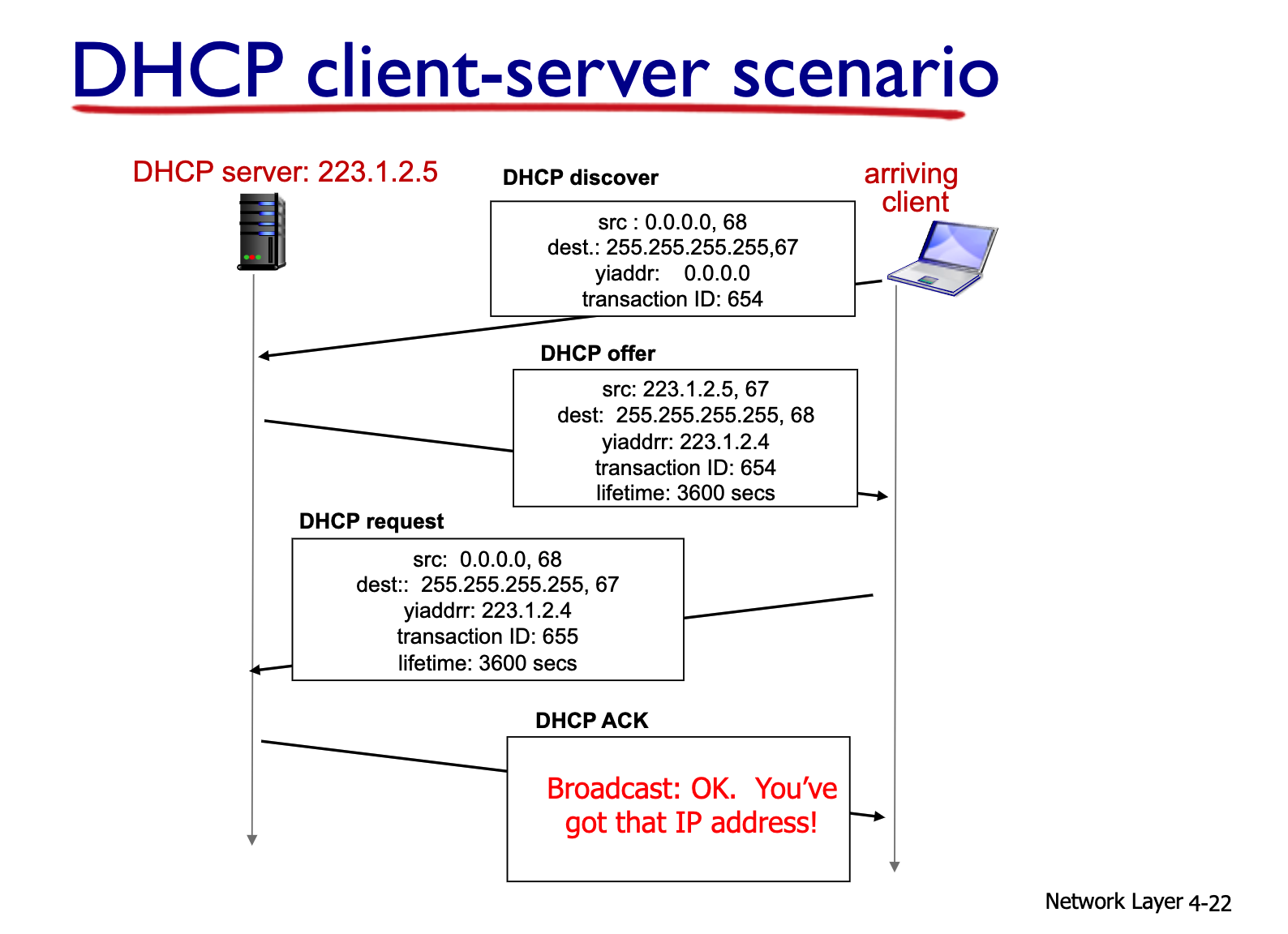
1. 호스트가 'DHCP discover' 메시지로 브로드캐스트(255.255.255.255)
2. DHCP 서버가 'DHCP offer'로 응답
3. 호스트가 IP 주소를 요청: 'DHCP request' 메시지
4. DHCP 서버는 IP 주소를 보냄: 'DHCP ack' 메시지
총 4번의 메시지를 주고 받는 과정을 수행하여 IP를 할당합니다.
+) 와이파이 네트워크 패스워드 입력 저장할 수 있는 이유는 동적인 IP 주소를 보고 구분하는 것이 아니라 노트북의 Wifi LAN 카드의 주소(MAC)를 기억하고 구분합니다.
만약 DHCP 서버가 외부 네트워크와 통신하고 싶다면?
DHCP 서버는 외부 네트워크와 통신하기 위해서는 IP주소 외에도 first-hop 라우터의 IP 주소, DNS server의 이름 & IP 주소, 서브넷 마스크 등의 정보가 추가적으로 필요합니다.
NAT(Network Address Translation)
NAT(Network Address Translation)는 라우터 등의 장비에서 다수의 사설 IP(Private IP)를 외부 IP(Public IP)로 네트워크 주소를 변환하는 기술을 말합니다.
NAT를 사용하는 이유?
만약, 어떤 라우터를 기준으로 사설 네트워크가 존재하고 네트워크 안에 엄청 많은 호스트가 있다면 호스트마다 IP 주소를 할당하면 굉장히 많은 IP 주소가 필요할 것 입니다. 하지만, 실제로는 외부 인터넷이 라우터 하나에 IP 하나를 할당해주므로 외부에서 보기에는 IP 주소가 하나만 있는 것으로 보이고 많은 IP의 할당이 필요하지 않습니다. 하지만 내부적으로는 호스트마다 다른 IP 주소를 사용하고 있습니다. 이 IP를 사설 IP 주소라고 부르고 이 주소는 내부 네트워크에서만 사용할 수 있는 IP 주소 입니다.
-> 그래서 이 내부 IP 주소를 외부 IP로 변환 및 매핑시켜주는 것이 NAT 입니다.
동작과정

1. 호스트에서 패킷에 (출발지의 Private IP, port#)(10.0.01, 3345)를 포함하여 (목적지 IP주소, port#)(128.119.40.186, 80)에 보낸다.
2. 호스트에서 NAT 라우터로 도착한 (10.0.0.1, 3345)(출발지 호스트 IP 주소, port#)와 (138.76.29.7, 5001)(NAT IP 주소, port#)를 테이블에 매핑시켜 기록을 해둔다.
3. 목적지로부터 NAT 라우터의 IP 주소로 (138.76.29.7, 5001) 응답이 들어온다.
4. NAT 라우터는 매핑시켜둔 테이블을 보고 (NAT IP 주소, port#)를 (호스트의 IP 주소, port#)로 변환한다.
장점
1. 모든 라우터에 물려있는 장비에 대해서 하나의 주소만 ISP로 부터 얻어오면 된다.
2. 외부 IP와 내부 IP가 독립적으로 설정되어 있으므로 내부 주소를 변경하더라도 외부에는 영향이 없다.
3. 2번과 마찬가지로 독립적이므로 외부 ISP를 변경하더라도 내부에는 영향이 영향이 없다.
4. 내부 네트워크 주소가 외부에 노출되지 않으므로 보안의 측면에서 장점이 있다.
의문점 및 논란
1. 외부 IP 주소는 하나밖에 없고 내부에는 내부 IP가 여러개가 있는데 전부 매핑이 가능한 이유 -> 외부에는 IP주소가 하나밖에 없고 내부에는 호스트가 여러 개 있는데 외부 IP 주소 하나로 내부의 수많은 호스트 IP를 매핑시킬 수 있는 이유는 포트(port) 번호로 구분하기 때문입니다. 즉, port 번호는 16-bit 필드이므로 이론적으로는 65535개의 호스트를 수용할 수 있습니다.
2. 라우터는 원래 계층 3까지만 처리해야 한다. -> 계층(Layer)으로 구분을 해서 다른 계층의 기능은 독립적으로 구현하는 것이 OSI 계층의 원칙인데 라우터는 3계층인 네트워크 계층의 장비로써 네트워크 계층까지만 처리해주어야 하지만 포트(port) 번호는 전송 계층의 기능이므로 영역을 침범하는 꼴이 됩니다. 그래서 NAT를 사용하면 사설망에서 여러개의 주소를 사용할 수 있다는 이점이 있지만 사실 주소 부족의 문제는 NAT가 아닌 IPv6로 해결하는 것이 맞습니다.
3. 포트 번호는 호스트를 구분하는 것이 아닌 프로세스를 구분하기 위해 사용하는 것이다. -> 포트 번호는 프로세스를 구분하기 위해 존재하는 것이므로 원래 목적과는 다르게 사용하고 있습니다. 그러므로, 개발자는 어플리케이션을 개발할 때 NAT가 사용될 가능성을 염두해야 합니다.
IPv6 주소체계
IPv6는 128-bit로 구성되어있으며 한 칸당 16-bit를 4자리의 16진수로 표현하여 8조각으로 구성된 IP 주소로 구성되어 있습니다.
ex) 2001:0db8:85a3:08d3:1319:8a2e:0370:7334
-> IPv4의 32-bit 길이의 IP 주소 공간(약 43억 개)은 이미 고갈된 상태이므로 128-bit 길이의 IPv6가 등장 하였고 IPv6는 2^128개의 주소공간을 수용할 수 있으므로 주소 부족의 문제를 해결하였습니다.
장점
1. 주소 공간이 엄청나게 많음.
2. header 형식 개선으로 우선순위 및 품질 따라 순차적 할당 기능 등의 QoS 지원.
3. 보안 기능을 기본적으로 제공.
IPv6 데이터 포맷

ver -> IPv4의 주소체계 혹은 IPv6의 주소체계 중에 어떤 버전을 사용하고있는지를 나타내며 IPv6이므로 값은 6입니다.
pri(트래픽 클래스) -> QoS용 필드며 기본 값은 0입니다.
flow label -> 같은 'flow'에 속한 데이터를 구별하기 위해 사용하는 필드로 기본 값은 0입니다.
payload len -> 페이로드(원본 데이터)의 길이를 나타냅니다.
next header -> IPv4는 upper layer였지만 IPv6는 next header를 정의합니다.
hop limit -> IPv4의 TTL 필드 명칭이 바뀐 것. 중계 가능한 라우터 수를 나타내고 중계할 때마다 값이 줄어들며 0이 되면 패킷의 수명이 다 한 것으로 보고 패킷을 폐기합니다.
sorurce, dest IP address -> 출발지와 목적지 IP 주소입니다. 128-bit인 이유는 IPv6를 사용하기 때문입니다.
IPv4에서 추가적인 변화
length -> 헤더길이가 고정되어있으므로 삭제되었고 payload len으로 대체되었습니다.
checksum -> 각 hop에서의 처리시간을 줄이기 위해 없어졌습니다. -> IPv4에서 datagram이 아닌 header에 대해서만 checksum을 했었고, 어짜피 전송 계층인 TCP나 UDP에서 checksum 계산을 하기 때문에 중복을 없애기 위해 제거되었습니다.
options -> options 필드가 제거되었습니다. -> 대신에 next header 필드에서 외부에 있는 options를 가리킬 수 있도록 할 수 있습니다.
identifier, flags -> 헤더에서 제거되고 확장 헤더에 포함되었습니다.
IPv4에서 IPv6로 전환하는 방법

flag day는 불가능 -> IPv4를 한번에 전부 없애고 IPv6로 변환하는 것은 불가능하므로 지금도 IPv4와 IPv6는 혼용하여 사용하고 있습니다.
터널링(turnneling) -> 현재 IPv4와 IPv6를 동시에 사용하고 있지만, 옛날의 기술은 최신 기술의 존재를 모르듯이 IPv4는 IPv6의 존재를 알지 못하므로 IPv4는 IPv6의 기능을 지원할 수 없습니다. 이를 해결하기 위해 터널링(turnneling)이라는 기법을 사용합니다. 터널링은 IPv4 라우터에서 IPv4의 datagram의 payload에 IPv6의 datagram을 넣어서 전달함으로써 IPv6와의 호환성을 해결합니다.
References
James Kurose, Keith W Ross, "Computer Networking: A Top-Down Approach", Pearson(2016)